Software Engineer, Data Scientist, Machine Learning Enthusiast

Projects
These projects represent the range of problems I've worked on throughout my career—from decoding dolphin vocalizations in the field to building ML systems serving millions of users. They span research, industry applications, and experimental interfaces. Some other stuff I did:
- Working on the dataset and the anonymisation for the the recsys challange 2016 and 2017 for Xing [Slides ECIR]
- A historically accurate sword fight in Hamburg Germany, with Pirates: Hamburg Sword Fight
- A small interactive tutorial on hidden Markov models: Simple Tutorial In Javascript and Tutorial Code In Python / Cython
- My old blog about machine learning and my life till ~2020: Blog
- Some of my code is actually on github: [:Github:] and [:Gist:]
Data Science @Hive
At Hive, I develop ML solutions for logistics challenges including delivery prediction, fulfillment optimization, and demand forecasting. I design and run experiments to validate model performance in production, working across the full stack from SQL data pipelines to deployed SageMaker models.
Tech: Python, SQL, AWS SageMaker
Software Engineer Machine Learning @Meta
Developed machine learning systems for audience targeting and ad optimization. Work included building ranking models, audience segmentation algorithms, and large-scale experimentation infrastructure.
Tech: Python, Hack, C++, SQL
Data Science @Shopify
Developed machine learning systems for Shopify's growth organization, including email marketing automation and predictive models for customer engagement. Built data models and ETL pipelines using dimensional modeling approaches.
Tech: PySpark, XGBoost, SQL
Data Science @Xing
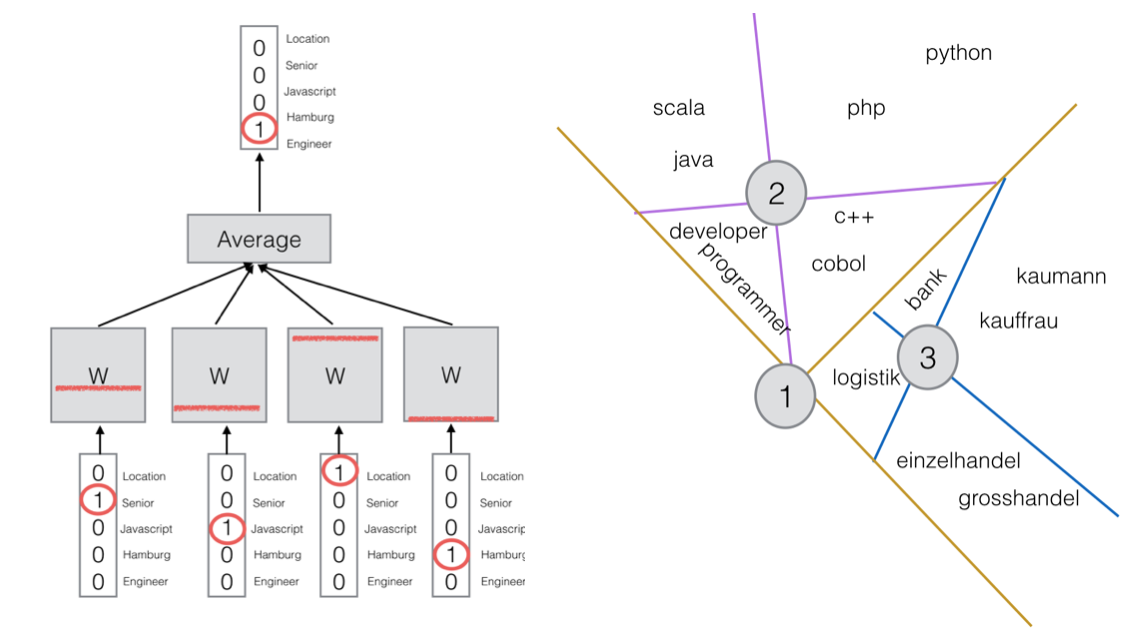
Built large-scale recommender systems for job and member matching on Germany's largest professional network. Developed ranking models using gradient boosting, created semantic search using word embeddings, and built classification systems for job categorization (industry, career level, discipline). Organized the ACM RecSys Challenge in 2016 and 2017. [RecSysNL] Talk
Tech: XGBoost, word2vec, Scala, PythonDolphin Communication
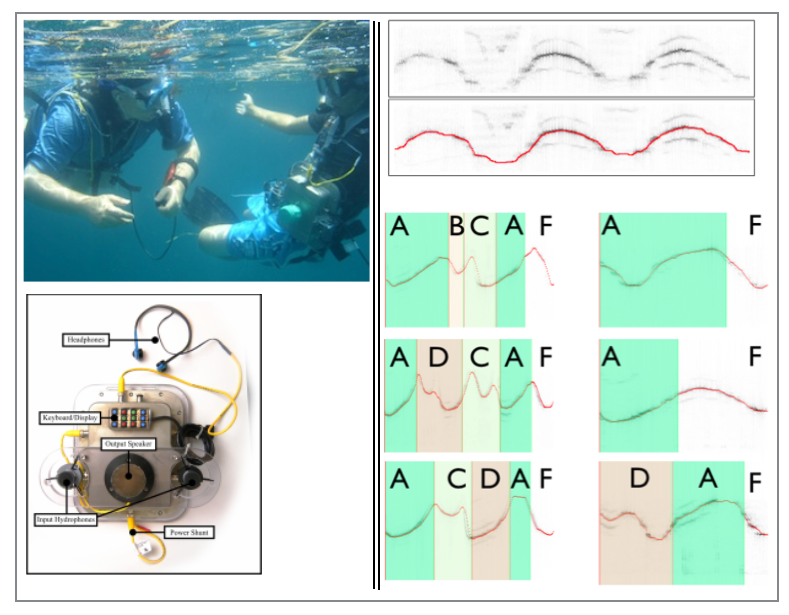
Challenge: Decode the structure of wild Atlantic spotted dolphin vocalizations without labeled data, and explore two-way human-dolphin communication.
Approach: I develop machine learning methods to discover atomic units in dolphin whistles and model how these units combine in context. Early work used mixture models of Hidden Markov Models for segmentation and pattern discovery. Recent work applies unsupervised deep learning (autoencoders) for acoustic modeling of dolphin communication.
Collaboration: Long-term partnership with Dr. Denise Herzing of the Wild Dolphin Project, who has studied wild dolphins in the Bahamas for over 30 years. Our team also built an underwater wearable computer (CHAT device) to enable real-time communication experiments in the field.
Impact:- Published in Animal Behavior and Cognition (2024, 2016)
- Featured in National Geographic
- Presented at ICASSP 2014, Interspeech 2016, IJCNN 2020
More high level talks can be found at: @ipat Georgia Tech
There is also a new google talk about our dolphin work at: Google
Furthermore, some of my code is here: Rust Pattern Discovery and here Mimic Generator and here WDP Data Science
MAGIC: Multiple Action Gesture Interface Creation
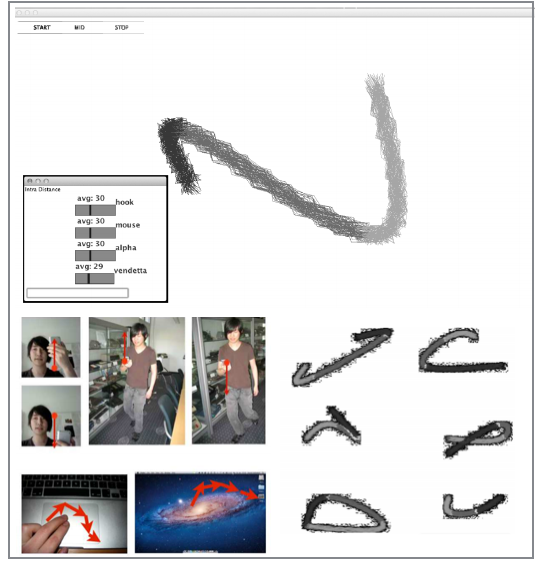
Challenge: Gesture-based interfaces need gestures that are intuitive and easy to perform, yet distinct enough from everyday movements to avoid false triggering.
Approach: MAGIC Summoning addresses this by building an "Everyday Gesture Library" (EGL)—a large database of unlabeled sensor data captured in real-world environments. The system indexes this data using multi-dimensional Symbolic Aggregate approXimation (SAX), enabling fast searches through natural human movements.
MAGIC suggests gestures with low collision probability against the EGL, ranked by brevity and simplicity. Once a gesture is selected, the system generates synthetic training examples for classifiers like Hidden Markov Models. If designers propose their own gestures, MAGIC estimates recognition accuracy and false positive rate by comparing against the natural movements in the EGL.
Impact: Published in Journal of Machine Learning Research (JMLR) and presented at Face and Gesture (FG) conference. The work influenced subsequent research in gesture recognition and false positive prevention.
Tech: SAX indexing, Hidden Markov Models, time series analysis, sensor data processing
Mobile Music Touch: Passive Haptic Learning
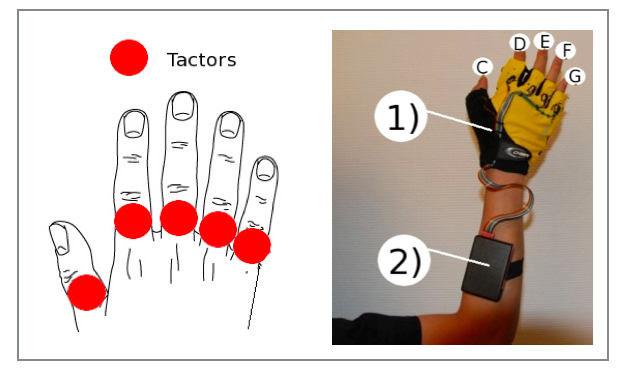
Challenge: Can people learn piano melodies passively while performing other tasks, using only haptic feedback?
Approach: Mobile Music Touch (MMT) is a wearable haptic instruction system consisting of fingerless gloves with vibrators on each finger, connected via Bluetooth to a mobile device. As a melody plays, vibrators activate to indicate which finger should press each note. Users wear the system while performing unrelated tasks (reading, walking, etc.), learning piano passages through repeated passive exposure.
Results: Two studies validated the approach. In the first study, 16 subjects used MMT for 30 minutes while performing a reading comprehension test. The haptic feedback condition significantly outperformed a control where the melody played without vibration. In the second study, participants with no piano experience could successfully repeat randomly generated passages after passive training, while experienced pianists often could not—suggesting the method works by building motor memory rather than musical understanding.
Impact: Published at CHI 2010 and ISWC 2010. Demonstrated that passive haptic learning can effectively teach motor sequences for musical performance.
Tech: Bluetooth, haptic interfaces, wearable computing, embedded systems